웹 서버의 역할

- 리소스에 대한 HTTP 요청을 받아서 클라이언트에게 컨텐츠를 제공
- HTTP 프로토콜 구현
- 웹 리소스 관리
- 웹 서버 관리 기능
- TCP 커넥션에 관리에 대한 책임은 운영체제와 같이함.
웹 서버의 형태
- 다목적 소프트웨어 웹 서버
- 임베디드 웹서버
다목적 소프트웨어 웹 서버
- 웹서버를 컴퓨터 시스템에 설치하고 실행
- 넷크래프트가 발표한 웹 서버 시장 점유율 (2021년 7월)

- nginx: 36.54%
- 아파치 : 25.61%
- 마이크로소프트 : 4%
임베디드 웹 서버
- 소비자용 제품에 내장되는 웹 서버
진짜 웹 서버가 하는 일
- 커넥션 맺기
- 원치 않는 클라이언트의 커넥션 요청은 안받을 수 있음
- HTTP 요청 받기
- 요청 처리하기
- 리소스에 접근하기
- HTTP 응답 만들기
- 응답을 클라이언트에게 보내기
- 로그 파일에 트랜잭션 로그 남기기
단계 1 : 클라이언트 커넥션 수락
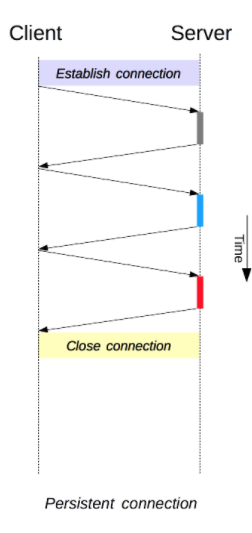
- 클라이언트가 서버와 지속 커넥션을 맺고 있다면, 그 커넥션 사용
- 커넥션이 없다면, 클라이언트와 서버간 새 커넥션 열기
1-1. 새 커넥션 다루기
- 클라이언트가 웹서버에 TCP 요청
- 웹 서버가 커넥션 맺기
- TCP 커넥션에서 IP 주소 추출하여 클라이언트 확인하기
- 웹 서버는 IP주소나 호스트명이 인가되지 않거나, 악의적이라고 판단하면 커넥션을 닫을 수 있다.
1-2 클라이언트 hostname 식별

- 웹 서버에서 클라이언트의 IP주소를 호스트명으로 변경하도록 설정
- 호스트명 룩업은 시간이 많이 걸리기 때문에 트랜잭션을 느리게할 수 있음.
--->호스트명 분석을 꺼두거나 특정 컨텐츠에 대해서만 켜둠 - Q. DNS의 역할은?정답호스트 이름 ---> IP주소로 변환
- Reverse DNS
- IP주소 ---> 호스트 이름으로 변환
- 왜 Reverse DNS로 호스트 이름을 찾을까?
- 로깅 : 누가 웹 사이트에 방문했는지 찾기 위함
- 대다수 서버 애플리케이션은 IP 기반으로 운용되므로 연결되는 컴퓨터들의 IP는 알 수 있지만 이게 어디의 컴퓨터에 붙은 IP인지는 사용자가 봐도 모른다. 컴퓨터의 위치(도시, 위도/경도 등)나 소속을 조회하는 서비스가 있기는 한데 좀 부정확하다. 대신에 리버스 도메인이 등록되어 있을 경우 클라이언트에 스크립트를 올리면 리버스 DNS Lookup 을 통해 해당 컴퓨터의 신원을 파악할 수 있으므로 좀 더 안전한 통신이 가능하다.
만약에 메일을 받을 때 SMTP 서버는 IP를 이용하여 전송하지만 SMTP 내용물엔 보낸 서버의 도메인이 있기 때문에 수신한 서버에서 송신처의 IP 주소를 리버스 DNS Lookup 을 통해 편지 안에 들어있는 서버의 이름(도메인)과 같은지 조회할 수 있다. 이런 식으로 메일의 피싱을 방지하는것은 기본. 2009년 9월 이후의 한국에서는 주요 통신사들이 개인 사용자들한테 할당되는 IP주소대역에 한하여 25번 포트를 네트워크 장비단에서 차단하고 있다.
1-3 ident 프로토콜로 클라이언트 사용자 알아내기
- ident : TCP client Identity Protocol
- TCP 요청을 시작한 사용자의 이름을 반환해주는 프로토콜
- 왜 ident 프로토콜로 사용자 이름을 확인할까?
- 웹 서버 로깅에 유용 : 로그 포맷의 두 번째 필드에 ident 사용자 이름을 담음
- identd의 정보는 충분히 위조될 수 있으며 서비스를 할 경우 불필요한 정보를 외부에 제공하게 되므로 보안과 속도등의 문제를 고려하여 identd는 서비스 하지 않는 것이 좋다.
단계 2 : 요청 메시지 수신
웹 서버는 네트워크 커넥션에서
- 데이터를 읽고
- 데이터를 파싱하여
- 요청 메시지를 구성한다.

- 요청 메시지 파싱할 때 하는 일
- 요청줄 파싱하여 method, URI, HTTP version을 찾는다.
- 메시지 헤더를 읽는다.
- 헤더의 끝을 의미하는 CRLF를 찾는다.
- 요청 본문을 읽는다.
웹 서버는 입력 데이터를 네트워크로부터 불규칙적으로 받는다.
따라서, 파싱해서 데이터를 이해할 수 있는 수준의 분량을 확보할 때까지 메시지 일부분을 메모리에 임시로 저장한다.
2-1. 메시지의 내부 표현
웹 서버는 파싱한 요청 메시지를 쉽게 다룰 수 있도록 내부의 자료 구조에 저장한다.
- 파싱된 데이터에 대한 포인터와 길이를 담는다.
- 헤더는 룩업 테이블에 저장되어 각 필드에 빠르게 접근할 수 있다.
2-2. 커넥션 입력/출력 처리 아키텍쳐
웹 서버는 아키텍쳐에 따라 요청을 처리하는 방식이 달라진다.
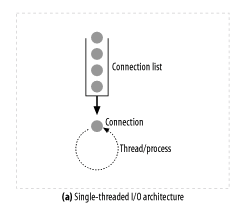
- 싱글 스레드 웹 서버
- 한 번에 하나씩 요청을 처리한다.
- 하나의 트랜잭션이 완료되면, 다음 커넥션을 처리한다.
- 하나의 트랜잭션 처리 중, 다른 요청은 무시되므로 서비스의 성능 문제가 생긴다.
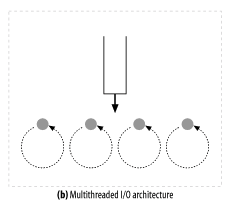
- 멀티 프로세스와 멀티 스레드 웹 서버
- 여러 프로세스와 스레드가 있기 때문에, 여러 요청을 동시에 처리할 수 있다.
- 스레드는 필요할 때마다 생기거나 스레드 풀(Thread Pool)에서 가져와서 요청에 할당할 수 있다.
- 너무 많은 프로세스와 스레드가 생겨서 리소스를 많이 소비하는 것을 막기 위해, 운영체제는 최대 스레드와 프로세스 수의 제한을 건다.
- 다중 I/O 서버
- 멀티 프로세스와 멀티 스레드 웹 서버의 문제점
- 클라이언트와 커넥션이 생길 때마다 프로세스/스레드를 할당하는 것은 많은 리소스가 할당된다.
- idle한 상태의 커넥션에 대해서도 스레드와 프로세스는 여전히 할당되어있다.
- 여러 커넥션을 모아두고, 상태를 감시한다.
- 에러가 발생하였는가
- 데이터를 받을 수 있는가
- 데이터를 보낼 수 있는가
- 상태가 변경되면 해당 커넥션에 대해 작업을 수행한다.
- 멀티 프로세스와 멀티 스레드 웹 서버의 문제점
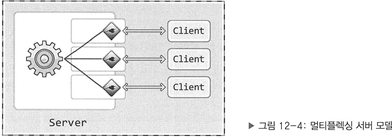
- 다중 멀티스레드 웹 서버
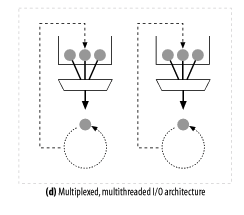
- 멀티 스레딩과 다중화(멀티 플렉싱)를 결합한 웹 서버
- 여러 개의 스레드는 커넥션의 부분집합을 감시하고, 변경이 일어나면 작업을 수행한다.
Q. 다중 멀티 스레드 웹 서버는 어떠한 이점을 살리기 위해 등장하였을까
A. CPU가 여러 개일 경우, 이 이점을 살리기 위해 등장
단계 3 : 요청 처리
- HTTP 요청 메시지에서 method, resource, header, body를 얻어내서 처리한다.
- 요청 처리에 대해서는 이 책의 나머지 장에서 설명
단계 4 : 리소스에 접근하기 (리소스 매핑과 접근)
웹서버는 리소스 서버다.
- 정적 컨텐츠 제공 : HTML 문서나 이미지 같은 미리 만들어진 컨텐츠 제공
- 동적 컨텐츠 제공 : 웹 애플리케이션 서버를 통해 동적 컨텐츠를 만들어서 제공
웹 서버가 클라이언트에게 컨텐츠를 전달하려면 요청 메시지의 URI에 맞는 컨텐츠나 컨텐츠 생성기를 찾아서, 리소스를 찾아야 한다.
- 정적 컨텐츠 리소스 매핑
- 디렉토리 요청에 대한 응답
- 동적 컨텐츠 리소스 매핑
- SSI
- 접근 제어
4-1. 정적 컨텐츠 리소스 매핑 : Docroot
클라이언트가 요청한 URI에 맞는 리소스를 서버에서 어떻게 찾을까? => Docroot
웹서버는 정적 컨텐츠를 제공하기 위해 파일 시스템에서 하나의 폴더를 웹 컨텐츠를 위해 예약(reserve) 해둔다.
- 요청 URI : /images/mountain.jpg
- 웹 서버의 docroot : /usr/local/httpd/files
- 서버 리소스 : 웹서버의 docroot + 요청 URI
- /usr/local/httpd/files/images/mountain.jpg
- 아파치의 httpd.conf
DocumentRoot /usr/local/httpd/files가상 호스팅된 docroot
가상 호스팅 웹 서버는 여러 웹 사이트를 호스팅하기 위해, 각 사이트마다 문서 루트를 둘 수 있다.
- HTTP Host 헤더나, IP 주소를 확인하여 docroot에 맞는 리소스를 제공한다.
- 아파치
<VirtualHost www.joes-hardware.com>
DocumentRoot /docs/hardware
<VirtualHost>
<VirtualHost www.joes-software.com>
DocumentRoot /docs/software
<VirtualHost>사용자 홈 디렉토리 docroots
사용자들이 한 대의 웹 서버에서 개인의 웹 사이트를 만들 수 있게 해준다.
- 슬래쉬(/)와 물결(~) 다음에 사용자 이름이 오는 것으로 시작하는 URI는 개인 문서 루트를 가리킨다.
- /~lillie/index.html
4-2. 디렉토리 목록
- 웹서버는 URI가 파일이 아닌 디렉토리인 요청을 받을 경우, 다음과 같은 선택지가 있다.
- 에러를 반환
- 색인 파일(index.html)을 반환
- 디렉토리 탐색 후 그 내용을 담은 HTML 파일 반환
- 일반적으로는 발견할 수 없는 파일이 드러날 수 있으므로, 이 설정을 끌 수 있음
4-3. 동적 컨텐츠 리소스 매핑
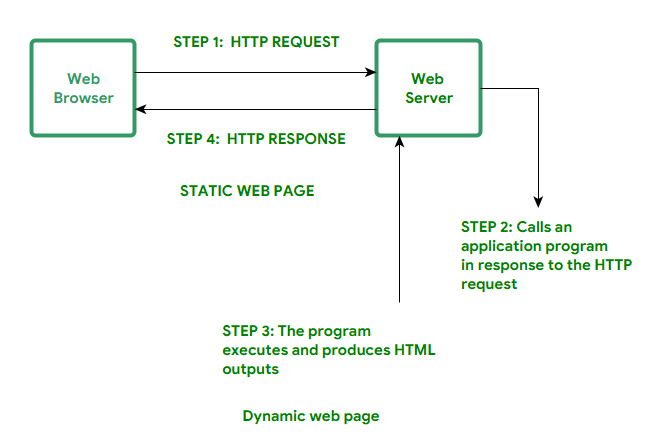
- 웹서버는 URI와 컨텐츠를 생성하는 프로그램을 매핑
- 아파치 설정
- URI 경로가 /cgi-bin/으로 시작할 경우 실행시킬 프로그램
ScriptAlias /cgi-bin /user/local/etc/httpd/cgi-programs4-4. 서버사이드 인클루드 (SSI)
- 동적 컨텐츠를 만드는 쉬운 방법
- SSI를 사용하면, HTML 문서에 동적인 내용을 추가할 수 있음
- cgi, jsp, servlet 같은 동적 페이지를 위한 기술을 사용하지 않아도, HTML 문서에 동적인 내용을 추가할 수 있음
- ssi 지시어
- 변수나, 실행 가능한 스크립트의 출력 값으로 치환
<!--#element attribute=value attribute=value ... -->- 예제
<!--#config timefmt="%A %B %d, %Y" -->
Today is <!--#echo var="DATE_LOCAL" -->4-5. 접근 제어
웹 서버는 리소스에 대한 접근을 제어하거나, 리소스에 접근하기 위한 비밀번호를 물어볼 수 있다.
단계 5. 응답 만들기
리소스를 클라이언트에게 전송하기 위해 응답 메시지를 만들어야 한다.
5-1. 응답 엔티티
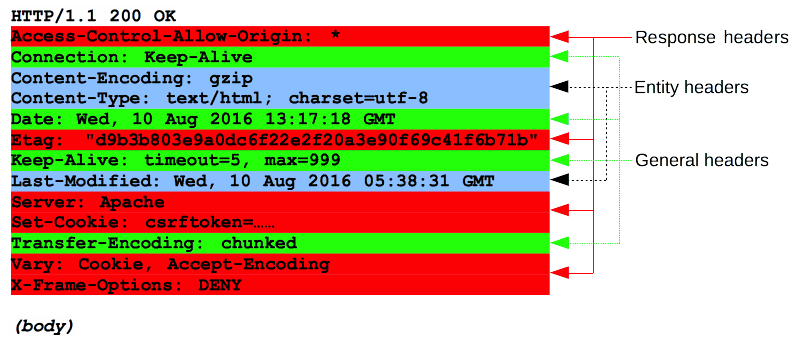
- General 헤더
- 메시지 전체에 적용
- Connection, Keep-Alive 헤더
- Response 헤더
- 상태줄에 들어가지 못한 서버에 대한 추가 정보 제공
- Access-Control-Allow-Origin, Server, Set-Cookie, Vary 헤더
- Entity 헤더
- 본문이 있는 응답은 Entity 헤더를 포함한다.
- Content-Type 헤더 : MIME 타입
- COntent-Length 헤더 : body의 길이
5-2. MIME 타입 결정하기
웹 서버는 응답 본문의 MIME 타입을 결정해야 한다.
- MIME 타입 결정 방법
- mime.types
- 파일 이름의 확장자를 사용
- 확장자별 MIME 타입이 담겨있는 파일을 탐색
- 가장 흔한 방법
- 매직 타이핑
- 파일의 내용을 검사해서 매직 파일(알려진 패턴에 대한 테이블)에 해당하는 패턴을 찾아 타입을 정함
- 파일이 표준 확장자 이름 없이 지어진 경우에 유용함.
- 유형 명시
- 파일 확장자와 관계 없이, 특정 파일이나 디렉토리 내의 파일에 대한 MIME 타입을 지정
- 유형 협상
- 한 리소스가 여러 종류의 MIME에 속하도록 설정
- mime.types
5-3. 리다이렉션
웹 서버는 리다이렉션 응답(3xx)을 반환할 수 있다.
- 리소스가 영구적으로 옮겨진 경우
- 301 Moved Permanently
- 임시로 리소스가 옮겨진 경우
- 303 See Other, 307 Temporary Redirect
- Fat URLs
- fat URL은 URL에 유저의 상태를 추가한 것을 말한다.
- 트랜잭션 간 상태를 유지할 수 있다.
- 서버는 상태 정보를 URL에 추가하여 클라이언트를 새 URL로 리다이렉트 시킨다.
- 예 - 아마존
- URL에서 사용자의 id를 url 뒤에 붙임<a href="/exec/obidos/tg/browse/-/229220/ref=gr_gifts/002-1145265-8016838">All Gifts</a><br>
- 부하 균형(Load Balancing)
- 과부화된 서버가 요청을 받으면, 덜 부하가 걸린 서버로 리다이렉트
- 친밀한 다른 서버가 있을 때
- 웹 서버가 클라이언트에 대한 정보를 갖고 있을 수 있음
- 요청한 클라이언트에 대한 정보를 갖고 있는 다른 서버로 리다이렉트
- 디렉토리 이름 정규화
- 클라이언트가 디렉토리 이름에 대한 URI를 요청하는데, 슬래쉬를 빠뜨렸다면 슬래쉬를 추가한 URI로 리다이렉트
단계 6. 응답 보내기
- 비지속적 커넥션 : 서버는 데이터 전송 후, 커넥션 닫음
- 지속적 커넥션 : 데이터 전송 후 커넥션 유지
단계 7. 로깅
- 트랜잭션 완료 후 어떻게 트랜잭션이 수행되었는지를 로그 파일에 기록
참고
'공부' 카테고리의 다른 글
| HTTP 2.0 (0) | 2022.08.15 |
|---|---|
| HTTP 1.1 Connection (0) | 2022.08.15 |
| HTTP 리다이렉션과 부하균형 (0) | 2022.07.31 |
| HTTP 쿠키 (0) | 2022.07.17 |
| mobx가 불변성을 지키지 않아도 되는 이유(mobx 내부 코드 살펴보기) (0) | 2022.05.29 |



